Building a RAG-Powered PDF Chatbot with LLMs and Vector Search
 Ever tried having a meaningful conversation with a 100-page technical document? Between dense specifications, scattered references, and complex terminology, extracting specific information from PDFs remains a persistent challenge. This post walks through how to build a RAG chatbot that can actually understand and discuss PDF documents, using Retrieval Augmented Generation (RAG), LLMs, and vector search. We'll explore how to create an intelligent PDF to AI chatbot and use Helicone to gain visibility into our system's performance.
Ever tried having a meaningful conversation with a 100-page technical document? Between dense specifications, scattered references, and complex terminology, extracting specific information from PDFs remains a persistent challenge. This post walks through how to build a RAG chatbot that can actually understand and discuss PDF documents, using Retrieval Augmented Generation (RAG), LLMs, and vector search. We'll explore how to create an intelligent PDF to AI chatbot and use Helicone to gain visibility into our system's performance.
The Problem: PDFs Are Hard to Query
PDFs are everywhere in business - technical specs, research papers, legal documents, you name it. While tools like ChatGPT can enhance PDF files through conversation, extracting specific information from large PDFs continues to be a challenge:
- Ctrl+F only works if you know exactly what to search for
- Reading the entire document for each question is time-consuming
- Important context often spans multiple sections
By leveraging natural language processing (NLP) and vector databases, we built a system that can retrieve relevant information from documents and generate coherent responses. Here's how we did it.
Architecture Overview
Let's dive into how a RAG chatbot works in practice. Our question-answering document retrieval LLM has several key components:
- PDF Processing: Converting unstructured PDFs into clean, usable text
- Text Chunking: Intelligently splitting text to maintain context
- Embedding Generation: Converting text into vector representations
- Vector Storage: Efficiently storing and searching embeddings
- Chat Interface: Managing conversation flow and context
- Monitoring: Tracking system performance and behavior
I'll walk you through each component, showing you how they fit together to create a powerful PDF chatbot.
The Building Blocks
1. PDF Text Extraction
First, we need to extract the raw text content from our PDF documents using the pdf-parse library:
// Function to extract text from PDF
async function extractText(filePath: string): Promise<string> {
const dataBuffer = fs.readFileSync(filePath);
const data = await pdfParse(dataBuffer);
return data.text;
}
2. Text Chunking
With the extracted text, we need to divide it into smaller chunks to optimize processing. Typically, each chunk is around 1000 characters. This ensures efficient embedding generation and retrieval.
// Function to chunk text into smaller segments
function chunkText(text: string, chunkSize: number = 1000): string[] {
const chunks: string[] = [];
let start = 0;
while (start < text.length) {
let end = start + chunkSize;
// Ensure we don't split in the middle of a word
if (end < text.length) {
const lastSpace = text.lastIndexOf(" ", end);
if (lastSpace > start) {
end = lastSpace;
}
}
chunks.push(text.slice(start, end));
start = end;
}
return chunks;
}
Explanation: The chunkText function iteratively slices the text into chunks, ensuring that words aren't split between chunks by identifying the last space before the chunk size limit.
3. Embedding Generation
The chunks are then transformed into numerical vectors using OpenAI's text-embedding-ada-002 embedding model.
// Function to generate embeddings
async function generateEmbeddings(
text: string,
questionNumber?: number
): Promise<number[]> {
const response = await openai.embeddings.create({
model: "text-embedding-ada-002",
input: text,
});
if (response.data && response.data.length > 0 && response.data[0].embedding) {
return response.data[0].embedding;
} else {
throw new Error("Failed to generate embeddings.");
}
}
An embedding is nothing but a text converted into a vector of numbers.
4. Vector Storage
These embeddings need to be stored so that we can retrieve them later. Vector data, as a type of spatial data, requires special handling because it represents information as points in multi-dimensional space where similar concepts cluster together. In this tutorial, we will be using FAISS (Facebook AI Similarity Search) for storing our vector data structures since it's lightweight and optimized for efficient similarity search. You can also explore other vector databases like Chroma, Pinecone, etc.
Note: Understanding semantic search vs vector search is key here - while semantic search relies on keywords and language patterns, vector search uses mathematical representations for more precise similarity matching.
// Initialize FAISS index
function initializeFAISS(dimension: number): FAISS.IndexFlatL2 {
const faissIndex = new FAISS.IndexFlatL2(dimension);
return faissIndex;
}
The initializeFAISS function creates a FAISS index using the L2 (Euclidean) distance metric. The dimension parameter corresponds to the size of the embedding vectors.
Adding Embeddings to FAISS:
// Add embedding to FAISS index
function addEmbeddingToFAISS(
faissIndex: FAISS.IndexFlatL2,
embedding: number[]
) {
faissIndex.add(embedding);
}
Saving the FAISS Index:
// Save FAISS index to disk
function saveFAISSIndex(faissIndex: FAISS.IndexFlatL2, indexPath: string) {
faissIndex.write(indexPath);
console.log("FAISS index saved to disk.");
}
To persist the FAISS index, this function writes the index to the specified indexPath, ensuring that embeddings aren't lost between sessions.
5. Chat Interface
This is the final components of our RAG chatbot. The chatbot provides an interactive command-line interface (CLI) where users can pose questions related to the PDF content. It leverages the OpenAI GPT-4o model to generate coherent and contextually relevant responses.
// Setup Readline for Chat Interface
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
prompt: "You: ",
});
let questionNumber = 1;
console.log("Chat with the PDF. Type your questions below.");
rl.prompt();
rl.on("line", async (line) => {
const query = line.trim();
if (query.toLowerCase() === "exit") {
rl.close();
return;
}
// ... [Handling the query] ...
questionNumber++;
rl.prompt();
}).on("close", () => {
console.log("Chat session ended.");
process.exit(0);
});
Processing User Queries:
// Inside rl.on("line") event handler
try {
console.log("Generating embedding for your query...");
// Generate embedding for the query
const queryEmbedding = await generateEmbeddings(query);
// Search in FAISS index
console.log("Searching FAISS index for relevant information...");
const searchResults = searchFAISS(faissIndex, queryEmbedding, 3); // Top 3 relevant chunks
resultRecorder.appendResults(searchResults);
return searchResults;
// Retrieve the most relevant text chunks
const relevantChunks = searchResults.labels.map((idx) => chunks[idx]);
// Create a prompt for OpenAI
const prompt = `Context:\n${relevantChunks.join(
"\n\n"
)}\n\nQuestion: ${query}\nAnswer:`;
// Get response from OpenAI
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{
role: "system",
content: "You are a helpful assistant.",
},
{
role: "user",
content: prompt,
},
],
max_tokens: 150,
temperature: 0.7,
});
if (
response &&
response.choices &&
response.choices.length > 0 &&
response.choices[0].message &&
response.choices[0].message.content
) {
console.log(`AI: ${response.choices[0].message.content.trim()}`);
} else {
console.log("AI: I couldn't find an appropriate answer.");
}
} catch (error: any) {
console.error("Error processing your query:", error.message);
}
Explanation:
Upon receiving a query, the chatbot:
- Generates an embedding for the user's question.
- Searches the FAISS index to find the top 3 most relevant text chunks.
- Constructs a prompt combining these chunks with the user's question.
- Sends this prompt to the OpenAI GPT model to generate a response.
- Displays the AI's answer or an error message if applicable.
And there you have it! 🎊 You've built a fully functional RAG chatbot. Now let's look at how to monitor its performance...
Monitoring Your RAG Pipeline
While building our RAG system, we quickly discovered that blind spots in LLM request monitoring could lead to performance issues and unexpected behaviors. Questions like "How to improve our prompt?", "Which queries are taking the longest?", and "Is my vector database returning the best results?" became critical to answer.
This is where Helicone comes in, providing observability for our rag chatbot. Let's look at how we integrated it...
Logging Requests
Throughout the code, Helicone's HeliconeManualLogger is used to log specific operations, such as embedding generation and FAISS searches. See the official documentation for more details.
const heliconeLogger = new HeliconeManualLogger({
apiKey: heliconeApiKey,
});
Explanation:
The HeliconeManualLogger is initialized with the Helicone API key. It wraps around critical operations and logs their details to Helicone.
Example: Logging a FAISS Search
const searchResults = await heliconeLogger.logRequest(
{
_type: "vector_db",
operation: "search",
vector: queryEmbedding,
},
async (resultRecorder) => {
const searchResults = searchFAISS(faissIndex, queryEmbedding, 3); // Top 3 relevant chunks
resultRecorder.appendResults(searchResults);
return searchResults;
},
{
"Helicone-Session-Id": sessionId,
"Helicone-Session-Path": `/chat/${questionNumber}`,
"Helicone-Session-Name": HELICONE_SESSION_NAME,
}
);
Explanation: When performing a search in the FAISS index, the operation details and results are logged. This includes the type of operation (search), the vector used for searching, and metadata such as session ID and path.
Putting It All Together
The main function orchestrates the entire process:
- Input Validation: Ensures a PDF file path is provided and exists.
- PDF Processing: Extracts and chunks text from the PDF.
- Embedding Generation: Creates embeddings for each text chunk.
- FAISS Indexing: Initializes the FAISS index, adds embeddings, and saves the index to disk.
- Chat Setup: Initializes the chat interface for user interaction.
- Query Handling: Processes user questions, retrieves relevant information, and generates AI responses.
async function main() {
try {
// 1. Validate input and extract PDF text
const pdfPath = process.argv[2];
if (!pdfPath) {
throw new Error("Please provide a PDF file path");
}
console.log("Extracting text from PDF...");
const text = await extractText(pdfPath);
// 2. Chunk the text
console.log("Chunking text...");
const chunks = chunkText(text);
// 3. Generate embeddings for each chunk
console.log("Generating embeddings...");
const embeddings = await Promise.all(
chunks.map((chunk) => generateEmbeddings(chunk))
);
// 4. Initialize and populate FAISS index
console.log("Initializing FAISS index...");
const dimension = embeddings[0].length;
const indexPath = path.join(__dirname, "faiss.index");
const faissIndex = initializeFAISS(dimension);
console.log("Adding embeddings to FAISS index...");
await heliconeLogger.logRequest(
{
_type: "vector_db",
operation: "insert",
vectors: embeddings,
},
async (resultRecorder) => {
embeddings.forEach((embedding) => {
addEmbeddingToFAISS(faissIndex, embedding);
});
saveFAISSIndex(faissIndex, indexPath);
},
{
"Helicone-Session-Id": sessionId,
"Helicone-Session-Path": `/pre-process`,
"Helicone-Session-Name": HELICONE_SESSION_NAME,
}
);
// 5. Set up chat interface
console.log("\nChat with your PDF! Type 'exit' to end the session.");
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
prompt: "You: ",
});
let questionNumber = 1;
rl.prompt();
// 6. Handle chat interactions
rl.on("line", async (line) => {
const query = line.trim();
if (query.toLowerCase() === "exit") {
rl.close();
return;
}
try {
// Generate embedding for the query
console.log("Processing your question...");
const queryEmbedding = await generateEmbeddings(query);
// Search for relevant chunks
const searchResults = await heliconeLogger.logRequest(
{
_type: "vector_db",
operation: "search",
vector: queryEmbedding,
},
async (resultRecorder) => {
const results = searchFAISS(faissIndex, queryEmbedding, 3);
resultRecorder.appendResults(results);
return results;
},
{
"Helicone-Session-Id": sessionId,
"Helicone-Session-Path": `/chat/${questionNumber}`,
"Helicone-Session-Name": HELICONE_SESSION_NAME,
}
);
// Get relevant text chunks
const relevantChunks = searchResults.labels.map((idx) => chunks[idx]);
// Generate response using OpenAI
const prompt = `Context:\n${relevantChunks.join(
"\n\n"
)}\n\nQuestion: ${query}\nAnswer:`;
const response = await openai.chat.completions.create(
{
model: "gpt-4o",
messages: [
{
role: "system",
content:
"You are a helpful assistant that answers questions based on the provided context.",
},
{
role: "user",
content: prompt,
},
],
},
{
headers: {
"Helicone-Auth": `Bearer ${process.env.HELICONE_API_KEY}`,
"Helicone-Session-Id": sessionId,
"Helicone-Session-Path": `/chat/${questionNumber}`,
"Helicone-Session-Name": HELICONE_SESSION_NAME,
},
}
);
if (response.choices[0].message?.content) {
console.log(`\nAI: ${response.choices[0].message.content.trim()}\n`);
} else {
console.log("\nAI: I couldn't generate a response.\n");
}
questionNumber++;
rl.prompt();
} catch (error: any) {
console.error("Error processing your query:", error.message);
rl.prompt();
}
}).on("close", () => {
console.log("\nThanks for chatting!");
process.exit(0);
});
} catch (error: any) {
console.error("An error occurred:", error.message);
process.exit(1);
}
}
// Start the application
main().catch(console.error);
Explanation: The main function ensures a seamless flow from PDF processing to user interaction, with Helicone monitoring each critical step.
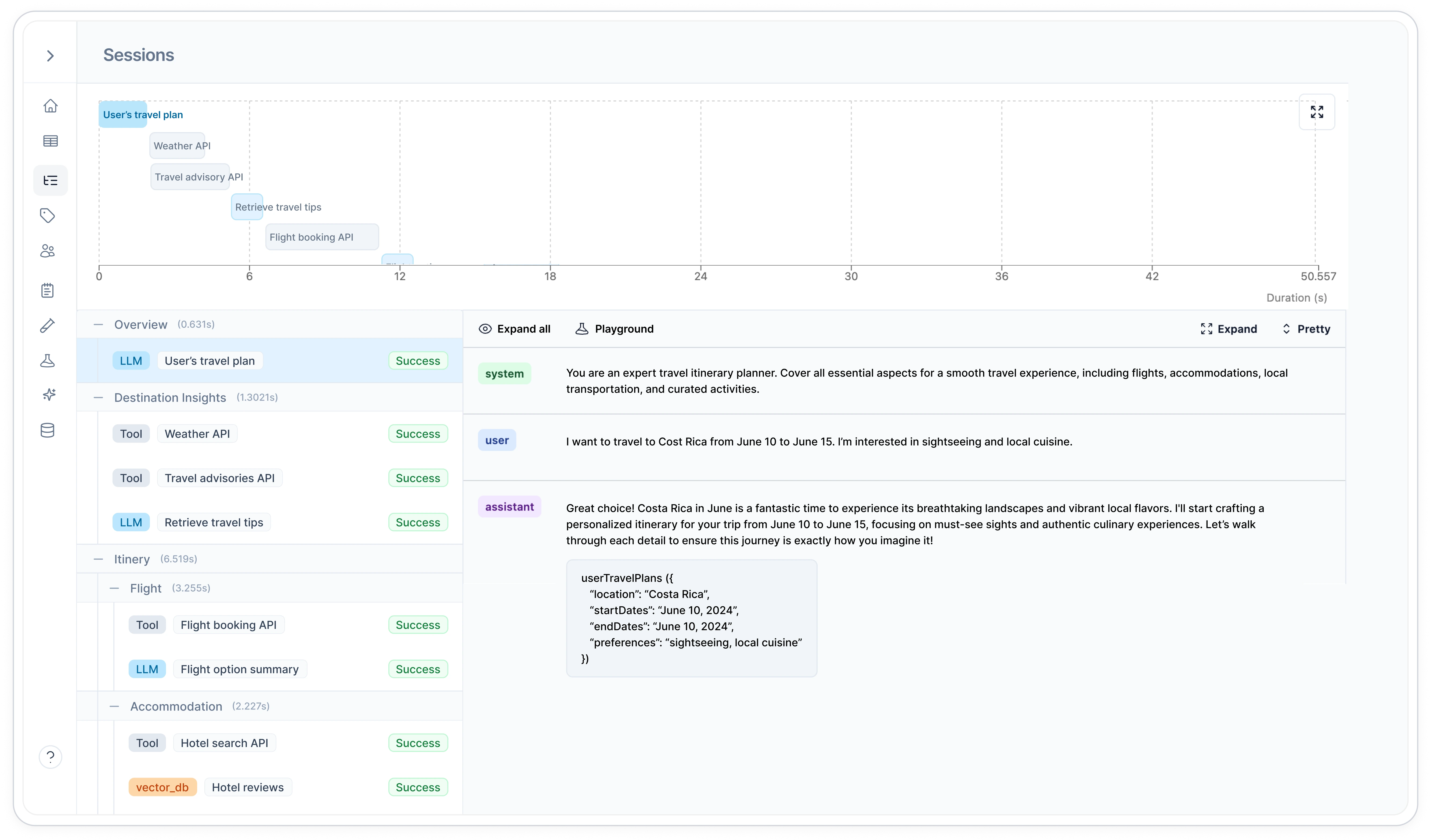
All of these requests are logged to Helicone and leverage session tracking. This groups related multi-step requests into a single session, allowing you to view the complete request/response chain in Helicone.
Example:
Conclusion
Remember that needle-in-a-haystack problem we started with? By combining RAG architecture with powerful monitoring tools like Helicone, we've built a solution that makes conversing with PDFs feel natural and efficient. The system doesn't just search for keywords, it understands context, maintains conversation flow, and learns from each interaction. Whether you're dealing with technical documentation, research papers, or legal documents, this architecture provides a foundation for building intelligent document interactions that feel less like searching through haystacks and more like having a knowledgeable assistant at your fingertips.